The devil is in the details
Let us think a real-life case, in which we have a lot of CSV files in one specific directory. For example, we may have transaction files (containing cash flow tables, date schedule tables, parameters) produced by some front office system batch on a daily basis. These files are then used as feed for a third-party analytical software for some intensive calculations. The only problem is, that some of the information in feed files is not in recognizable form for third-party software. In a nutshell, feed files may contain some specific strings, which should be replaced with another string.
War stories
The next question is how to do this operation quickly and on a safe manner? Needless to say, there are pretty much as many approaches as there are people performing this heartbreaking operation. Personally, I have used
- find-and-replace strategy with notepad++, until the amount of files to be processed and parameters to be replaced grew a bit too large.
- custom batch script, until I realized that the script was sometimes not working as expected, by either leaving some cases out from replacement operations or resulting incorrect replacements. The scariest part was, that the script was actually working well most of the time.
- custom Powershell script (created by someone else), which was using hard-coded configurations for all replacement strings and all strings which should be replaced. All configurations (hosted in source code file) needed to be set in a specific order. This was actually working well up to a point, where those hard-coded configurations should have been changed to correspond changes made in other systems. Moreover, execution times were a bit too high.
Finally, I decided to create my own program for handling this task.
United we fall, divided we stand
After learning a bit of parallel algorithms, I soon realized that this kind of a scheme (due to task independency) would be suitable candidate for implementing parallelism, in order to improve program execution speed. Each source file (containing transaction information) has to be processed separately and all key-value pairs (string-to-be-replaced and corresponding replacement string) can be stored in concurrent-safe concurrent unordered map as string pairs.
FileHandler.h
This header file is consisting free functions for all required file handling operations.
#pragma once // #include <filesystem> #include <fstream> #include <string> #include <map> #include <vector> #include <algorithm> #include <sstream> // namespace MikeJuniperhillFileSystemUtility { std::string ReadFileContentToString(const std::string &filePathName) { std::string data; std::ifstream in(filePathName.c_str()); std::getline(in, data, std::string::traits_type::to_char_type( std::string::traits_type::eof())); return data; } // void WriteStringContentToFile(const std::string& content, const std::string &filePathName) { std::ofstream out(filePathName.c_str()); out << content; out.close(); } // std::vector<std::string> GetDirectoryFiles(const std::string& folderPathName) { std::vector<std::string> directoryFiles; using itr = std::tr2::sys::directory_iterator; for (itr it = itr(folderPathName); it != itr(); ++it) { directoryFiles.push_back(static_cast<std::string>((*it).path())); } return directoryFiles; } // // replace all substrings found (stringToBeReplaced) with another // string (replacementString) in a given string (string) std::string ReplaceAllSubstringsInString(const std::string& string, const std::string& stringToBeReplaced, const std::string& replacementString) { std::string result; size_t find_len = stringToBeReplaced.size(); size_t pos, from = 0; while (std::string::npos != (pos = string.find(stringToBeReplaced, from))) { result.append(string, from, pos - from); result.append(replacementString); from = pos + find_len; } result.append(string, from, std::string::npos); return result; } // read key-value pairs into std::map // (key = string to be found and replaced, value = replacement string) std::map<std::string, std::string> ReadKeysFromFileToMap(const std::string& filePathName, char separator) { std::map<std::string, std::string> keys; std::ifstream file(filePathName); std::string stream; std::string key; std::string value; // while (std::getline(file, stream)) { std::istringstream s(stream); std::getline(s, key, separator); std::getline(s, value, separator); keys.insert(std::pair<std::string, std::string>(key, value)); } return keys; } } //
Tester.cpp
First, there has to be a directory containing all source files, which are going to be processed by file processing program. Also, there has to be a specific file, which contains key-value pairs (key = string to be found and replaced, value = replacement string) for all desired string replacement cases. Main program is creating file processors into vector container (there will be as many processors as there are source files to be processed). Then, main program is executing all file processors. A single file processor is first reading source file information into string, looping through all key-value pairs and checking whether any occurences are to be found, performing string replacements and finally, writing modified information back to original source file.
#include <ppl.h> #include <concurrent_vector.h> #include <concurrent_unordered_map.h> #include <functional> #include <memory> #include <chrono> #include <iostream> #include "FileHandler.h" // namespace MJ = MikeJuniperhillFileSystemUtility; // using Files = std::vector<std::string>; using Pair = std::pair<std::string, std::string>; using Keys = std::map<std::string, std::string>; using GlobalKeys = concurrency::concurrent_unordered_map<std::string, std::string>; using ProcessorMethod = std::function<void(void)>; using FileProcessor = std::shared_ptr<ProcessorMethod>; // // create file processor FileProcessor Factory(const GlobalKeys& keys, const std::string& filePathName) { // deferred execution ProcessorMethod processor = [=, &keys](void) -> void { std::string fileUnderProcessing = MJ::ReadFileContentToString(filePathName); for each (Pair pair in keys) { // extract key (string to be found and replaced) and value (replacement string) Pair keyValuePair = pair; std::string key = std::get<0>(keyValuePair); std::string value = std::get<1>(keyValuePair); // // check if key exists in a given string (containing all information in current file) size_t found = fileUnderProcessing.find(key); if (found != std::string::npos) { // if exists, replace key with value fileUnderProcessing = MJ::ReplaceAllSubstringsInString(fileUnderProcessing, key, value); } } // finally write change into original file MJ::WriteStringContentToFile(fileUnderProcessing, filePathName); }; FileProcessor fileProcessor = FileProcessor(new ProcessorMethod(processor)); return fileProcessor; } // int main(int argc, char* argv[]) { // get required path strings from command line std::string keysFilePathName = argv[1]; std::string fileDirectoryPathName = argv[2]; // // create list of files (files to be modified) and list of key-value pairs // (key = string to be found and replaced, value = replacement string) Files files = MJ::GetDirectoryFiles(fileDirectoryPathName); char separator = ','; Keys keys = MJ::ReadKeysFromFileToMap(keysFilePathName, separator); // // insert keys into concurrency-safe unordered map GlobalKeys Keys; std::for_each(keys.begin(), keys.end(), [&](Pair pair) -> void { Keys.insert(pair); }); // // create file processors : // each processor will be processing exactly one file (given filePathName) // by looping through all keys-value pairs (in GlobalKeys) and searching for // all occurrences of substring (key) and replacing this with another string (value) std::vector<FileProcessor> processors; std::for_each(files.begin(), files.end(), [&](std::string filePathName) -> void { processors.push_back(Factory(Keys, filePathName)); }); // // execute file processor method for all file processors auto start = std::chrono::steady_clock::now(); concurrency::parallel_for_each(processors.begin(), processors.end(), [](FileProcessor fp) -> void { (*fp)(); }); auto end = std::chrono::steady_clock::now(); auto timeElapsed = std::chrono::duration_cast<std::chrono::seconds>(end - start); std::cout << "processed in " << timeElapsed.count() << " seconds" << std::endl; // return 0; } //
User settings
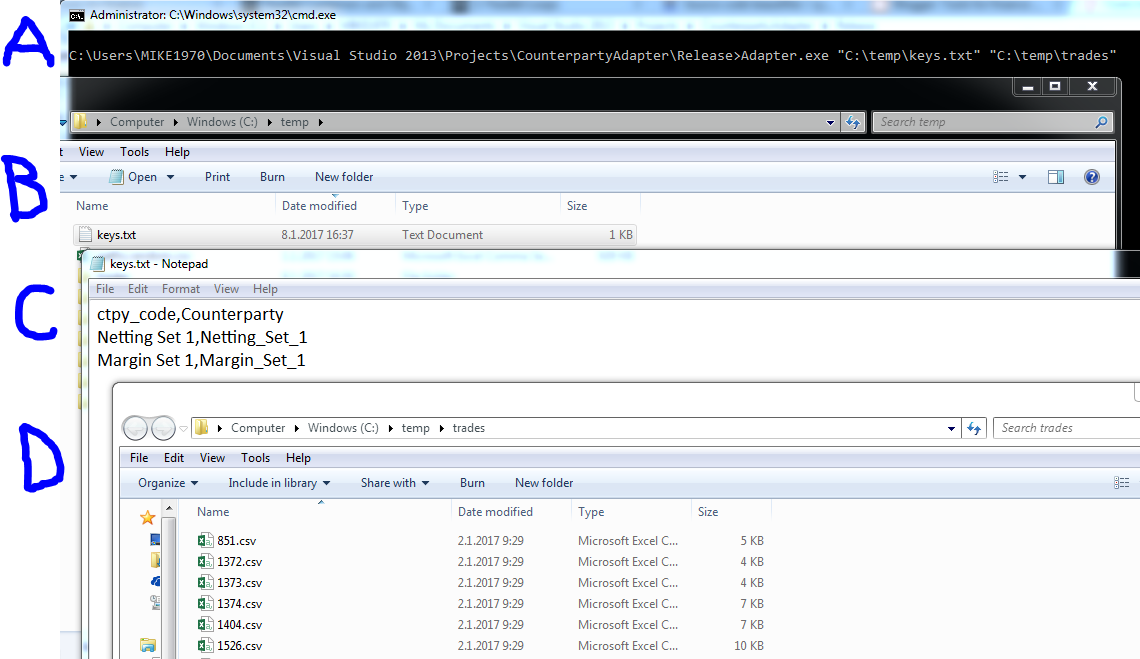
In this particular case, a picture is worth more than thousand words.
A : arguments for executable to be used with command prompt
B : directory for key-value pairs file
C : the content of key-value pairs file
D : directory for source files.
Finally, thanks a lot again for reading this blog.-Mike
No comments:
Post a Comment