PRDC note
Essentially, PRDC note can be thought as taking a leveraged position on FX forward curve. Floating coupon rate is a function of FX rates, usually defined as follows.
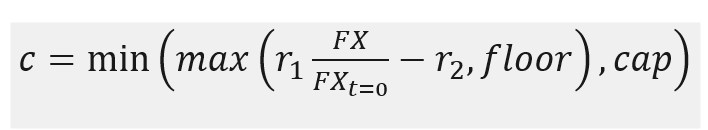
Additional FX term (at t=0) will scale FX rate used in coupon and is usually set to be equal to FX forward at inception. Mathematically, this changes the slope of coupon payoff and therefore, adding desired leverage to the product.
Model for FX stochastics
From pricing perspective, we need to get a view on FX forward curve. This can be simulated by using Garman-KohlHagen stochastic process for an exchange rate, which is available in QuantLib-Python library. In essence, this process is Geometric Brownian Motion, with an added term for foreign interest rate. We will use this model, even it does not necessarily fully reflect the statistical properties of exchange rate.
Applying Ito's rule to Geometric Brownian Motion, gives us the following solution for an exchange rate S observed at time t.

Python program
In order to implement completely new instrument and corresponding new pricing engine in QuantLib, one should first implement these in QuantLib C++ library by following carefully the designed Instrument-Engine scheme and then, interface these newly created C++ types back to Python by using swig. However in here, we will skip the previous approach completely. Instead, we just take "all the useful bits and pieces" available in QuantLib-Python library and use these to implement our own valuation code.
QuantLib-Python object building documentation by David Duarte is available in here.
The complete code is available in here.
Libraries
The following two libraries are being used.
import numpy as np import QuantLib as ql |
FX path generator
Path generator implements spot rate simulation, based on a given 1D stochastic process. Generated path is exactly in line with the dates given in coupon schedule. Note, that the exact number of paths to be generated has not been defined in this class. Whoever will be the client for this class, can request as many paths as desired.
class PathGenerator: def __init__(self, valuation_date, coupon_schedule, day_counter, process): self.valuation_date = valuation_date self.coupon_schedule = coupon_schedule self.day_counter = day_counter self.process = process # self.create_time_grids() def create_time_grids(self): all_coupon_dates = np.array(self.coupon_schedule) remaining_coupon_dates = all_coupon_dates[all_coupon_dates > self.valuation_date] self.time_grid = np.array([self.day_counter.yearFraction(self.valuation_date, date) for date in remaining_coupon_dates]) self.time_grid = np.concatenate((np.array([0.0]), self.time_grid)) self.grid_steps = np.diff(self.time_grid) self.n_steps = self.grid_steps.shape[0] def next_path(self): e = np.random.normal(0.0, 1.0, self.n_steps) spot = self.process.x0() dw = e * self.grid_steps path = np.zeros(self.n_steps, dtype=float) for i in range(self.n_steps): dt = self.grid_steps[i] t = self.time_grid[i] spot = self.process.evolve(t, spot, dt, dw[i]) path[i] = spot return path
Monte Carlo pricer
Monte Carlo pricer class will use path generator for simulating requested number of FX paths. A call for method npv will trigger coupon rates simulation. Simulated rates will then be corrected by taking into account of intro coupon. Finally, a series of cash flows will be created, based on calculated coupon rates and schedule dates.
class MonteCarloPricerPRDC: def __init__(self, valuation_date, coupon_schedule, day_counter, notional, discount_curve_handle, payoff_function, fx_path_generator, n_paths, intro_coupon_schedule, intro_coupon_rate): self.valuation_date = valuation_date self.coupon_schedule = coupon_schedule self.day_counter = day_counter self.notional = notional self.discount_curve_handle = discount_curve_handle self.payoff_function = payoff_function self.fx_path_generator = fx_path_generator self.n_paths = n_paths self.intro_coupon_schedule = intro_coupon_schedule self.intro_coupon_rate = intro_coupon_rate # self.create_coupon_dates() def create_coupon_dates(self): self.all_coupon_dates = np.array(self.coupon_schedule) self.past_coupon_dates = self.all_coupon_dates[self.all_coupon_dates < self.valuation_date] n_past_coupon_dates = self.past_coupon_dates.shape[0] - 1 self.past_coupon_rates = np.full(n_past_coupon_dates, 0.0, dtype=float) self.remaining_coupon_dates = self.all_coupon_dates[self.all_coupon_dates > self.valuation_date] self.time_grid = np.array([self.day_counter.yearFraction(self.valuation_date, date) for date in self.remaining_coupon_dates]) self.grid_steps = np.concatenate((np.array([self.time_grid[0]]), np.diff(self.time_grid))) self.n_steps = self.grid_steps.shape[0] if(self.intro_coupon_schedule==None): self.has_intro_coupon = False else: self.intro_coupon_dates = np.array(self.intro_coupon_schedule) self.remaining_intro_coupon_dates = self.intro_coupon_dates[self.intro_coupon_dates > self.valuation_date] self.n_remaining_intro_coupon_dates = self.remaining_intro_coupon_dates.shape[0] if(self.n_remaining_intro_coupon_dates > 0): self.has_intro_coupon = True else: self.has_intro_coupon = False def simulate_coupon_rates(self): self.simulated_coupon_rates = np.zeros(self.n_steps, dtype=float) for i in range(self.n_paths): path = self.fx_path_generator.next_path() for j in range(self.n_steps): self.simulated_coupon_rates[j] += self.payoff_function(path[j]) self.simulated_coupon_rates = self.simulated_coupon_rates / self.n_paths if(self.has_intro_coupon): self.append_intro_coupon_rates() self.coupon_rates = np.concatenate((self.past_coupon_rates, self.simulated_coupon_rates)) self.n_coupon_cash_flows = self.coupon_rates.shape[0] def append_intro_coupon_rates(self): for i in range(self.n_remaining_intro_coupon_dates): self.simulated_coupon_rates[i] = self.intro_coupon_rate def create_cash_flows(self): self.coupon_cash_flows = np.empty(self.n_coupon_cash_flows, dtype=ql.FixedRateCoupon) for i in range(self.n_coupon_cash_flows): self.coupon_cash_flows[i] = ql.FixedRateCoupon(self.all_coupon_dates[i+1], self.notional, self.coupon_rates[i], self.day_counter, self.all_coupon_dates[i], self.all_coupon_dates[i+1]) self.coupon_leg = ql.Leg(self.coupon_cash_flows) redemption = ql.Redemption(self.notional, self.all_coupon_dates[-1]) self.redemption_leg = ql.Leg(np.array([redemption])) def npv(self): self.simulate_coupon_rates() self.create_cash_flows() self.redemption_leg_npv = ql.CashFlows.npv(self.redemption_leg, self.discount_curve_handle, False) self.coupon_leg_npv = ql.CashFlows.npv(self.coupon_leg, self.discount_curve_handle, False) date = [payment.date() for payment in self.coupon_leg] amount = [payment.amount() for payment in self.coupon_leg] amount[-1] += self.notional pv = [ql.CashFlows.npv(np.array([payment]), self.discount_curve_handle, False) for payment in self.coupon_leg] pv[-1] += self.redemption_leg_npv self.cash_flow_table = np.array([date, amount, pv]) return self.coupon_leg_npv + self.redemption_leg_npv |
Hard-coded factory
def process_factory(): today = ql.Settings.instance().evaluationDate domestic_curve = ql.FlatForward(today, ql.QuoteHandle(ql.SimpleQuote(0.01)), ql.Actual360()) domestic_curve = ql.YieldTermStructureHandle(domestic_curve) foreign_curve = ql.FlatForward(today, ql.QuoteHandle(ql.SimpleQuote(0.03)), ql.Actual360()) foreign_curve = ql.YieldTermStructureHandle(foreign_curve) fx_vol = ql.QuoteHandle(ql.SimpleQuote(0.1)) fx_vol_curve = ql.BlackVolTermStructureHandle(ql.BlackConstantVol(today, ql.NullCalendar(), fx_vol, ql.Actual360())) fx_spot = ql.QuoteHandle(ql.SimpleQuote(133.2681)) return ql.GarmanKohlagenProcess(fx_spot, foreign_curve, domestic_curve, fx_vol_curve)
Main program
Main program creates all required components (JPY discount curve, process, schedules, generator and pricer) and then requests npv and cash flow table as Numpy ndarray (indexing: [0] = coupon dates, [1] = cash flows, [2] = present values of cash flows).
today = ql.Date(11, 4, 2023) ql.Settings.instance().evaluationDate = today # create JPY discount curve discount_curve = ql.FlatForward(today, ql.QuoteHandle(ql.SimpleQuote(0.005)), ql.Actual360()) discount_curve_handle = ql.YieldTermStructureHandle(discount_curve) # create FX process process = process_factory() # create schedules for coupon- and intro coupon payments effectiveDate = ql.Date(3, ql.September, 2015) terminationDate = ql.Date(3, ql.September, 2041) coupon_schedule = ql.MakeSchedule(effectiveDate, terminationDate, ql.Period(6, ql.Months), backwards=True, calendar=ql.TARGET(), convention=ql.ModifiedFollowing) intro_coupon_termination_date = ql.Date(3, ql.September, 2016) intro_coupon_schedule = ql.MakeSchedule(effectiveDate, intro_coupon_termination_date, ql.Period(6, ql.Months), backwards=True, calendar=ql.TARGET(), convention=ql.ModifiedFollowing) # create FX path generator fx_path_generator = PathGenerator(today, coupon_schedule, ql.Actual360(), process) # create PRDC pricer notional = 300000000.0 intro_coupon_rate = 0.022 n_paths = 10000 prdc_payoff_function = lambda fx_rate : min(max(0.122 * (fx_rate / 120.0) - 0.1, 0.0), 0.022) prdc_pricer = MonteCarloPricerPRDC(ql.Settings.instance().evaluationDate, coupon_schedule, ql.Actual360(),notional, discount_curve_handle, prdc_payoff_function, fx_path_generator, n_paths, intro_coupon_schedule, intro_coupon_rate) # request results npv_ccy = prdc_pricer.npv() print('PV in CCY: {}'.format(npv_ccy)) jpy_eur = 145.3275 npv_eur = npv_ccy / jpy_eur print('PV in EUR: {}'.format(npv_eur)) print() print('Cash flow dates: {}'.format(prdc_pricer.cash_flow_table[0])) print() print('Cash flows: {}'.format(prdc_pricer.cash_flow_table[1])) print() print('Present values of cash flows: {}'.format(prdc_pricer.cash_flow_table[2]))
Thanks for reading this blog.
-Mike










